代码
https://github.com/VictorJiangXin/Linear-CRF/
Motivation
研一下选修了宗成庆老师的「自然语言处理」,课程要求完成一系列的大作业,然而已是拖延症晚期的我,一直将其晾在一边,直到今天,才真正开始启动项目。由于实验室资源匮乏,没有GPU,因此只能选择使用传统方法能够完成的大作业,最终确定中文分词实验。
话不多说,先看前沿论文,看看当前中文分词的baseline。
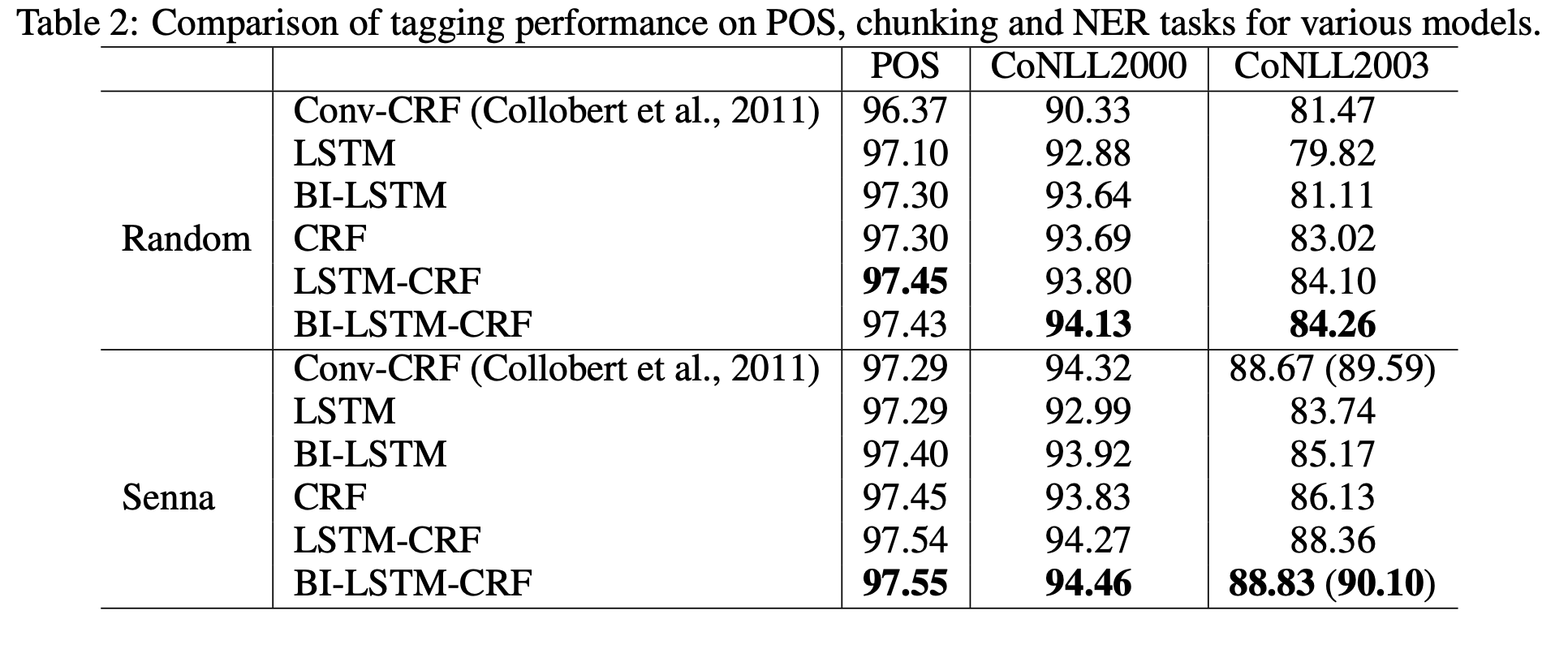
由上图可知,2015年前,使用BI-LSTM+CRF模型,中文分词的效果最好,其相对准确度最高。但将其与传统的CRF方法比较,竟然只是个位数的提升!!!而且还要耗费巨大的计算量,使用GPU进行训练,这实在不是个划算的生意!总体而言,深度学习在自然语言处理方向的应用,对于机器翻译的提升最大,而其他比较传统的NLP任务,比如句法分析,实体标注等,使用传统的方法已经能够有非常好的效果了。因此,果断选择使用CRF(条件随机场),来完成中文分词任务。
目前,已经有非常多的开源CRF包了,而且也非常好用,直接用这些包完成中文分词任务将会十分简单。但是,直接使用CRF包,就太没挑战性了,也不能够促进对知识点的理解,重点是——没有情怀!搞科研,最重要的是情怀,^_^,要有将知识转为实践的能力。因此,本次决定用Python实现一个简单的Linear-CRF模型(线性链条件随机场),用于完成中文分词任务,Let’s Go!
CRF 条件随机场
要了解CRF,最好先了解下隐马尔科夫模型,可以先看看隐马尔科夫模型在分词上的应用 ,先对HMM有个简答的了解,然后再理解CRF可以更容易些。
首先,什么是CRF(条件随机场)?如下图所示,白色的点表示为$Y$,黑色的点表示为$X$,设$X$与$Y$是随机变量,$P(Y|X)$是在给定$X$的条件下$Y$的条件概率分布,若随机变量$Y$构成了一个由无向图$G=(V,E)$表示的马尔可夫随机场,即:
则称$P(Y|X)$为条件随机场。简而言之,就是随机变量$Y$所在的节点的随机变量,概率分布只与与其连接的节点有关。
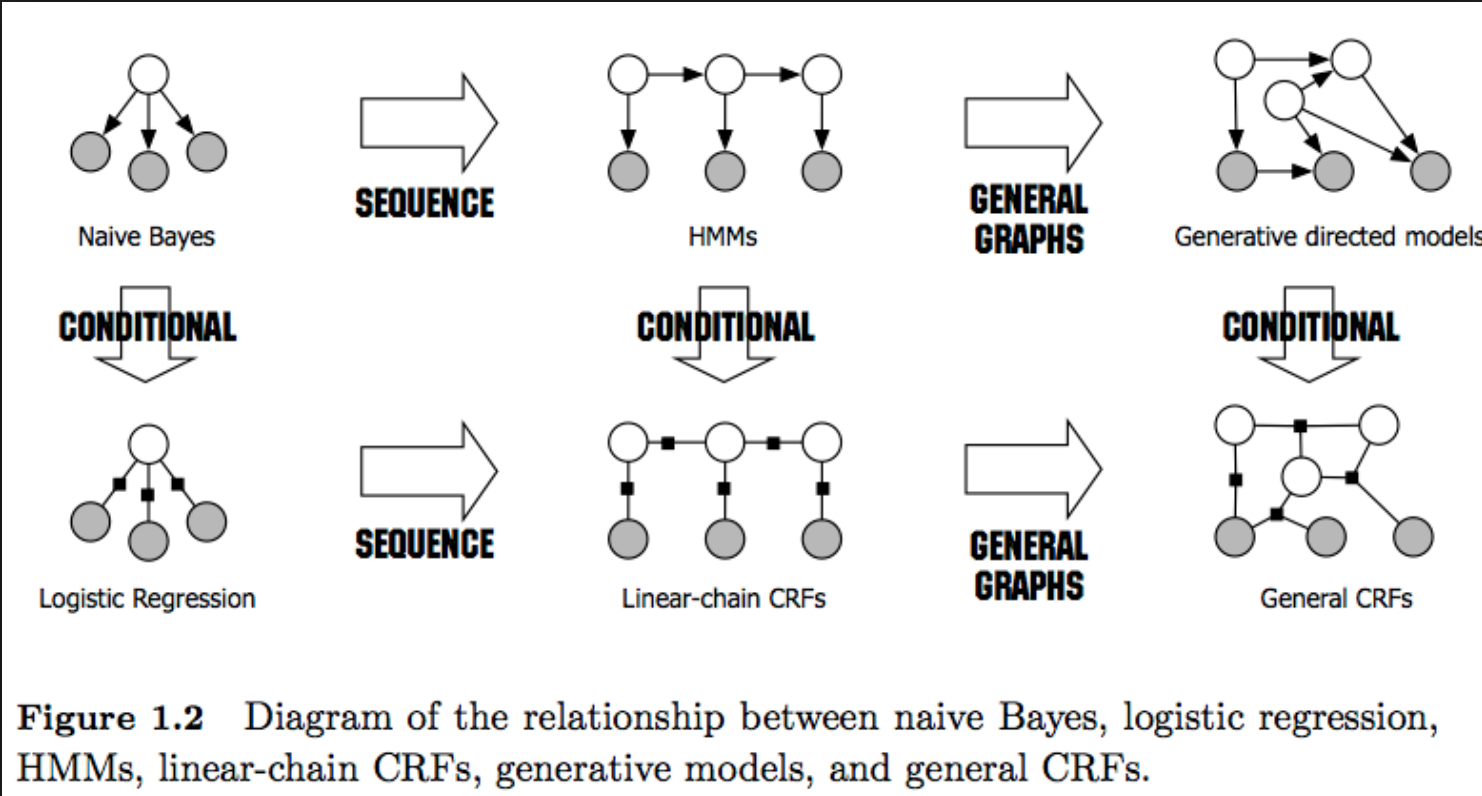
Linear CRF(线性链条件随机场)
线性条件随机场是条件随机场的一种,其结构如上图的中间所示,随机变量$Y_t$的分布,除了给定的随机变量$X$外,只与其前后的随机变量$Y_{t-1}$以及$Y_{t+1}$有关。本次分词任务所用的即为线性条件随机场,后文所介绍皆以线性条件随机场为主,所称CRF也都指线性条件随机场,后文将不再赘述。
线性链条件随机场的参数化形式
设$P(Y|X)$为线性链条件随机场,则在随机变量$X$取值为$x$的条件下,随机变量$Y$取值为$y$的条件概率具有以下形式(上面所说的$x$,$y$均表示一个序列):
其中,
上式中,$t_k$和$s_l$为特征函数,$\lambda_k$和$s_l$代表的是对应的权值,$Z(x)$对应的是规范化因子。其中,特征函数一般随任务自由设定,其值一般为0或者1,而条件随机场需要训练的就是相关的权重值,比如$\lambda_k$与$s_l$。
简单点,表达的方式简单点
由于条件随机场在同一特征的各个位置中都有定义,可以对同一个特征在各个位置进行求和,将局部特征函数转化为一个全局特征函数,这样可以将条件随机场写成权值向量和特征向量的內积形式,即其简化表示,首先将转移特征与状态特征用统一的符号进行表示,设有$K_1$个转移特征,$K_2$个状态特征,$K=K_1+K_2$,记:
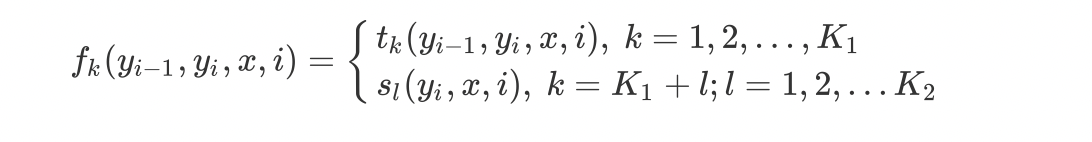
同理,用$w_k$表示特征$f_k(y,x)$的权值,即:
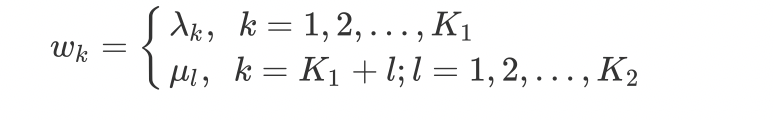
因此,条件随机场可表示为:
我们常用矩阵去进行表示并进行相关计算,以$w$表示权重向量,即:
而求得位置$i$对应的所有的特征表示为:
该等式表示的是位置$i$对应的相关特征,比如$F_1(x,y)=[1,0,0,0,1,0,0]$表示对于给定的$x$,$y$序列在序列的第一个位置,其具有相应的$f_1$特征,$f_5$特征。因此,此时条件随机场的计算可以表示为:
比如:
为了计算$P(y|x)$,先计算各个位置对应的特征值,为:
同理,再去求$Z(x)$可以得到相关值,但$Z(x)$有其他计算方法,后面会再介绍。
只用公式太枯燥了,让我们举个栗子吧!以分词任务为例,$x$表示语句”今晚/月色/真/美”,而$y$采用常用的分词标注次,即为$y={B,E,I,S}$,其中$B$表示词语的开头,$E$表示词语的结尾,$I$表示词语的中间词,$S$表示单个词,则栗子中$y$对应的序列应该为$BEBESS$。而特征只举简单的栗子,只对单个词取特征,因此我们的特征对应为:
这些特征只有在满足条件时为1,否则为0。而右边的$\lambda$以及$\mu$是模型的参数,则对于此时,$P(y|x)$可表示为:
上式值写了部分,其含义是,在第一个位置’今’,上面所列举的特征只有$f_1(y_1=B,x[1]=’今’)=1$,其余的特征对应为0,而第二个位置’晚’,上面所列举的特征只有$f_6(y_2=E,x[2]=’晚’)=1$。同理,可推导其他位置对应的特征,从而得到当前CRF模型下,对于给定$x$以及$y$对应的概率值。而$Z(x)$的要针对所有的$y$的可能进行累加,也就是类似语句”今晚/月色/真/美”对应的标记为$EEBESS$,$EEEESS$等等,所有的可能性,在当前CRF模型(给定特征权重参数情况下),计算得到的概率的和。
条件随机场的矩阵形式
条件随机场可以由矩阵表示,假设$P_w(y|x)$是线性链条件随机场,表示给定观测序列$x$,相应的标记序列$y$的条件概率,引进特殊的起点和终点状态标记$y_0=start$,$y_{n+1}=end$,$y$可表示为$m$中形式即$y$的表示形式可以为$Y=(Y_1,Y_2,…,Y_m)$,则此时的$P_w(y|x)$可以通过矩阵形式表示。
对观测序列$x$的每一个位置$i=1,2,…,n+1$,定义一个$m$阶矩阵:
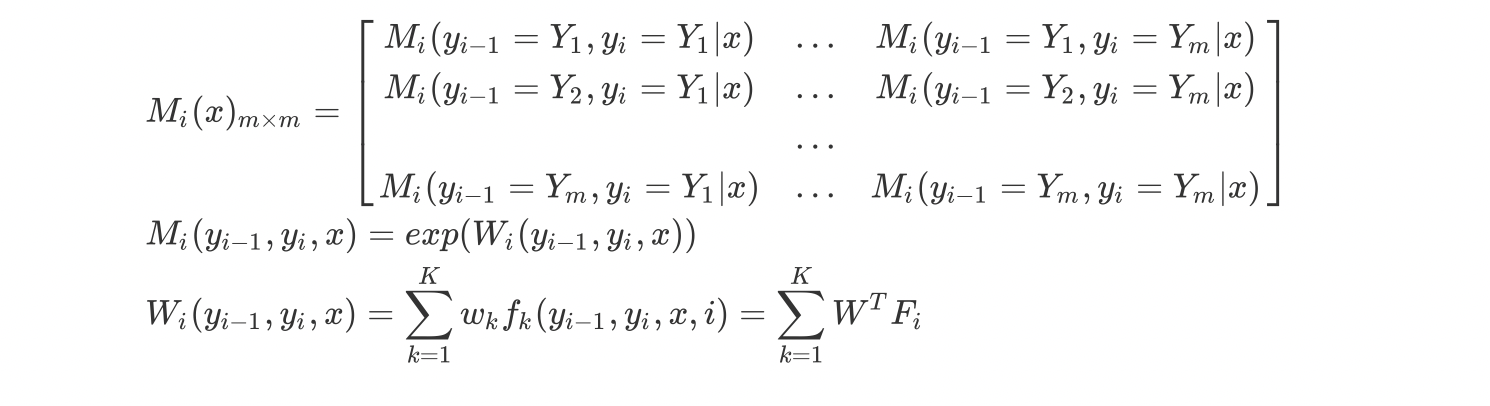
因此,此时的条件概率$P(y|x)$可以表示为:
$Z(x)$规范化因子,则可表示为$(n+1)$个矩阵乘积中的元素:
为什么 $x$ 序列只有 $n$ 个元素,但是这里M矩阵有$n+1$个呢?因为,我们人为的添加了start与end。此时要注意,由于每个序列的start是确定的,因此,对于$M_1(x)$,只有$M_1(y_{0}=start, y_1)$ 不为零,其他的都为0。对于$M_{n+1}$只有$M_{n+1}(y_n, y_{n+1}=end)$ 为1, 其他都为0。
注意!!$M_i(x)$与$M_i(y_{i-1},y_i,x)$的区别,$M_i(x)$表示的是$m \times m$的矩阵,而$M_i(y_{i-1},y_i,x)$只是该矩阵中,$y_{i-1},y_i$为确定表示的一个元素。
举个栗子,给定一个线性链条件随机场,观测序列$x$,状态序列$y$,$i=1,2,3$,$ n=3$,标记$y_i={1,2}$ 假设$y_0=start=1$,$y_4=stop=1$,各个位置的随机矩阵分别为:
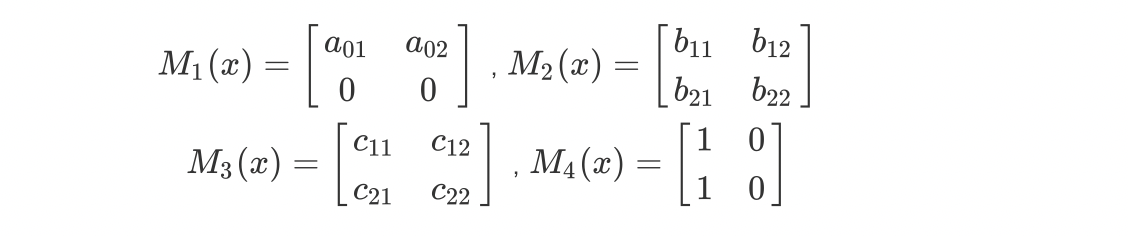
从start到end对应的各个路径的非规范化概率分别是:
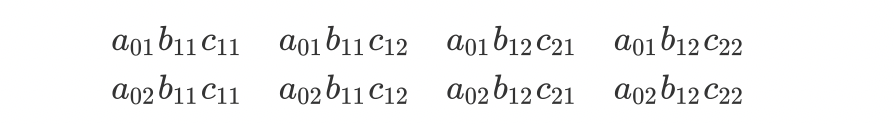
而计算矩阵$M_1(x)M_2(x)M_3(x)M_4(x)$,其第一行第一列对应的元素为:
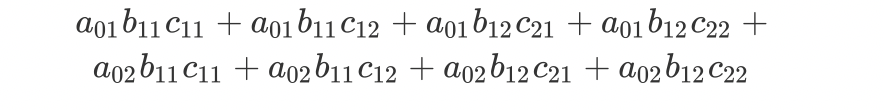
条件随机场的概率计算问题
前向向量
对于每个位置$i=0,1,..,n+1$,定义前向向量$\alpha_i(x)_{m\times 1}$,其表示给定序列$x$,前$(i-1)$个位置的标签可以为任意的,但第 $i$ 个标签为 $y_i$ 的概率:
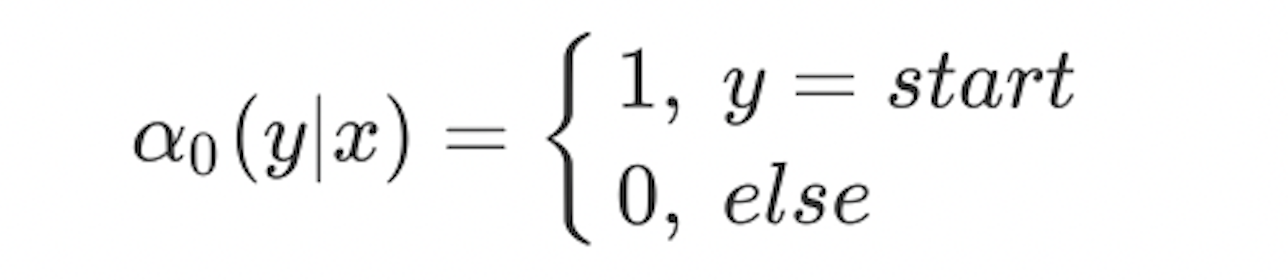
也可表示成
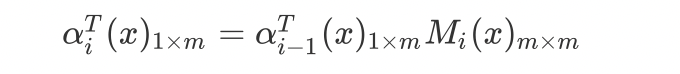
因此,$\alpha_0(x)$只有在start对应的标志处为1,其余为0。$\alpha_{n+1}(x)$ 只有在end对应的标志处存在值,其值为$z(x)$。
后向向量
对于每个位置$i=0,1,..,n+1$,定义前向向量$\beta_i(x)_{m\times 1}$,其表示给定序列$x$,第$i$个元素为$y_i$,从第$i$到$n$为任意的标签的概率:
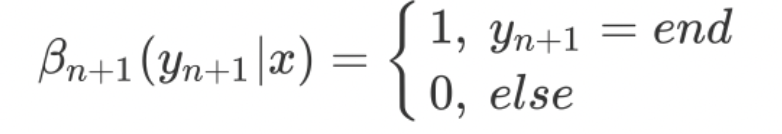
也可表示为:
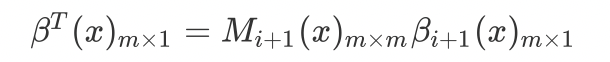
由前向向量以及后向向量可以得到:
因此,$\beta_{n+1}(x)$ 只有在end标志处为1,其余为0。$\beta_0(x)$ 只有在start标志处为$z(x)$,其余为0。
概率计算
与HMM模型一样,已知前向-后向向量的定义,很容易计算标记序列在位置$i$是标记$y_i$的条件概率,以及在位置$i-1$与$i$是标记$y_{i-1}$和$y_i$的条件概率:,
条件随机场的预测问题
与HMM的预测问题一样,条件随机场的预测问题也用Viterbi(维特比)算法,进行推测,其原理如下图所示。每次一次都更新每一位置对应的所有可能显示结果对应的可能性,然后选取最大的一个最为当前位置的路径。
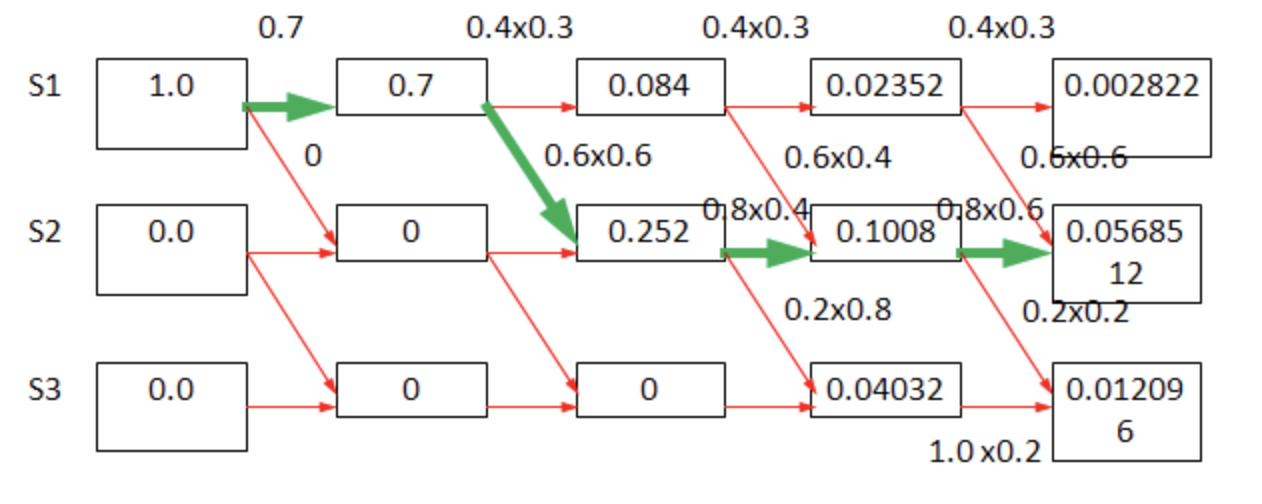
因此相关算法可以描述为:
输入:模型特征向量$F(x,y)$和权值向量$W$,观测序列$x=(x_1,x_2,…,x_n)$。
输出:最优路径$y^*=(y_1^*,y_2^*,…,y_n^*)$
- 初始化
- 递推,对$i=1,2,3…,n$
- 终止
- 返回路径
训练
CRF训练是最重要的一点,主要用于训练得到CRF的权重矩阵,看了很多博客和李航的《统计学习方法》都写的很复杂,看完也不知道如何进行训练,最后还是在CRF的WIKI上,找到相关开源CRF的指导手册(万能的维基百科!),终于找到了一种实用的用于训练的算法。它采用L-BFGS优化算法进行优化,在给定训练集$D=(X,Y)$的情况下,其对数似然为:
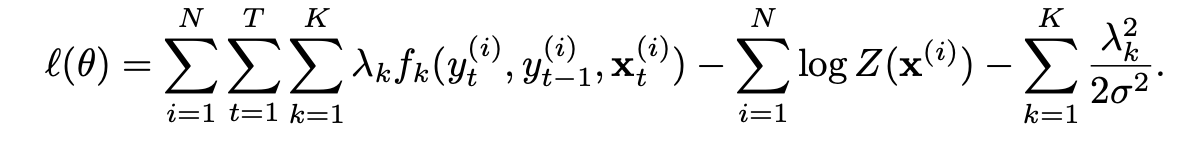
对应于之前的公式,其实左边等式的和就是$\log P_w(y|x)$,具体看条件随机场的矩阵部分。
其相应的对数形式下,损失函数的梯度表示为:
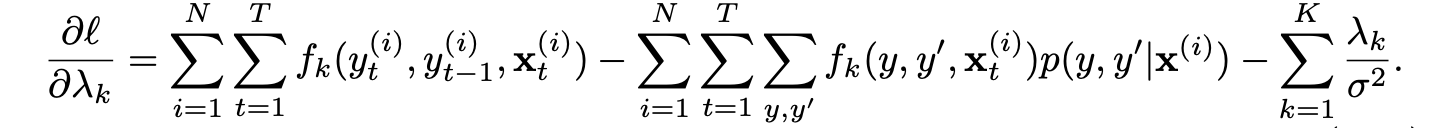
第一项就是预料中,对于该语料,每一特征出现的次数。第二项则是,对于某一个给定的$x$,先求出所有的$p(i, y_{i-1}, y_i)$,这个可以通过前向概率,后向概率计算得到,具体看前文。然后求出对应的$f_k(y_{i-1}, y_i)$,最后得到相应的值。相关伪代码如下:
1 | def feature_at(x, y_pre, y_now, k): |
但是,在实际代码中,每次遍历一次特征是非常慢的,由于给定一个序列 $x$ ,其具有的特征是确定的,因此,可以直接找到对应的 $k$ 进行运算,具体看代码。
P.S CRF的训练,要求使得对数似然函数最大化!!!不是最小化,如果使用最小化策略去优化,一定要对他们取负。
基于线性链条件随机场的中文分词
在理解完成上述CRF各个公式的含义及概念后,则问题就变得简单了,就是按照上述提供的公式,将其计算出来。
中文分词特征是什么?
条件随机场中特征一般分为两种,一种是U特征,也就是状态特征;另一种是B特征,也就是转移特征。U特征常常表示为(U, pos_shif, y,x,index, word),其一般为:
1 | (U, -1, y, x, index, word, tag): |
即该特征对应的是文字本身的前后文信息。
B特征常常表示为(B,tag_pre, tag_now),其一般为:
1 | (B, tag_pre, tag_now) |
也就是说B特征表示的是变量y包含的状态转移信息。
而特征的数量为($U_{count}\times V_{word}\times m+ m \times m$)。其中$U_{count}$表示U特征提取的位置数目,比如只提取文字前1个,当前文字,文字后一个,则此时$U_{count}=3$,$V_{word}$为语料库中文字数量,$m$表示$y$的标签数,即$y$的表现形式,对于每个文字,都有存在你一种表现形式的可能,因此要乘以m。B特征代表前一个标签到当前标签的转移概率。
推测分词结果
在训练好模型后,按照Viterbi算法,推到出最可能的y序列,则得到相应的分词结果。
训练
虽然我们已经知道了最大似然函数的表示以及梯度的计算公式,但是实际上,并不需要我们自己去写相关的优化器,直接使用传统的机器学习框架提供的minimize工具就行了,比如scipy.optimize.minimize。将相关的约束函数及对应导数作为参数输入,既可以得到相应的结果。
Corpus(语料库)
北京大学语料库:https://pan.baidu.com/s/1gd6mslt
GitHub作者liwenzhu,于14年发布于GitHub,总词汇量在7400W+,可以用于训练。https://github.com/liwenzhu/corpusZh
参考文献
- http://flexcrfs.sourceforge.net/flexcrfs.pdf (flexcrfs是Python版本的开源包,该文档是其使用手册,本文引用了手册中的Train部分,即损失函数以及梯度计算。
- L-BFGS优化方法介绍
- https://people.cs.umass.edu/~mccallum/papers/crf-tutorial.pdf
- 宗成庆-《自然语言处理》课件-2019年春-计算所
- 胡玥-《自然语言处理》课件-2018年秋-信工所