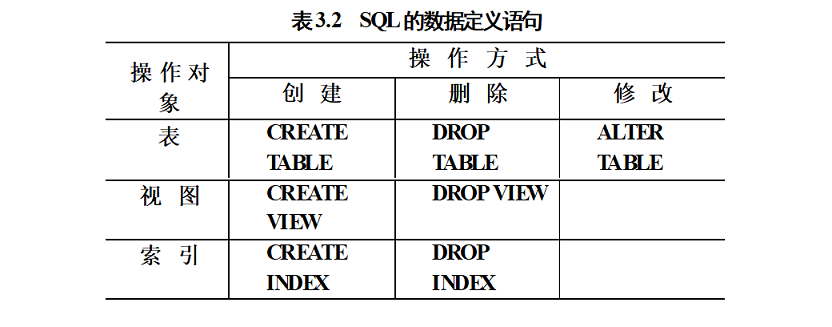
数据库定义语句
CREAT语句_建表
CREAT语句用于创建数据库、表、视图等操作。语句格式如下:1
2
3
4CREATE TABLE <表名>(
<列名><数据类型>[<列级完整性约束条件>],
<列名><数据类型>[<列级完整性约束条件>],
<表级完整性约束条件>);
<表级完整性约束条件>: 涉及一个或多个属性列的完整性约束条件
常用完整性约束:
- 主码约束: PRIMARY KEY
- 参照完整性约束:
- 唯一性约束: UNIQUE
- 非空值约束: NOT NULL
- 取值约束: CHECK
- 数据类型: 在SQL Server中,有几种主要的类型——文本、数字、二进制数据和日期
- 文本类型
- CHAR(size) 保持固定长度的字符串。n的取值:1-8000
- VARCHAR(size) 保持可变长度的字符串。在括号中指定字符串的最大长度,最多为8000个字符,效率没CHAR高
- TEXT 最多存放长度为 2^31-1 个字符的字符串
- NCHAR(n) 固定长度,Unicode字符串数据。n的取值1-4000
- NVARCHAR(n) 可变长度,Unicode字符串数据。n的取值范围1-4000
- NTEXT 长度可变的Unicode数据,字符串最大长度为2^30-1
- 数字类型
- BIT 0/1或NULL的数据类型
- BIGINT 8字节存储的INT数据类型
- INT 4字节存储的INT数据类型
- SMALLINT 2字节存储的INT数据类型
- TINYINT 1字节存储的INT数据类型
- DECIMAL[(P[,S])] []表示可选择的。固定精度和小数位数,p表示精度,s表示小数位数
- FLOAT[(n)] 浮点数,其中n用于存储flaot数值尾数的尾数,用于确定精度
- 二进制类型
- BINARY(n) 固定长度,n的取值:1~8000
- VARBINARY(n) 可变长度,最多为长度n,n的取值:1~8000
- IMAGE 长度可变的二进制数据,从0到2^31-1个字节
- 时间类型
- TIME 00:00:00.0000000到23:59:59:9999999
- DATE 0001-01-01到9999-12-31
- SMALLDATETIME 日期范围:1900-01-01到2079-06-06 时间范围:00:00:00到23:59:59
- DATATIME 日期范围:1753-01-01到9999-12-31 时间范围:00:00:00到23:59:59.997
- DATATIME2 日期范围:0001-01-01到9999-12-31 时间范围:00:00:00到23:59:59.9999999
- 文本类型
举例:创建一个学生表,包括学号、姓名、性别、年龄及所在系。其中学号不能为空,且唯一,姓名取值也唯一。
1 | CREATE TABLE Student( |
CREAT语句_建索引
建立索引是加快查询速度的有效手段。
索引建立方式:
- DBMS自行建立
- PRIMARY KEY
- UNIQUE
- DBA或表的属主(建表的人)根据需要建立。
维护索引:DBMS自动完成
语句格式:CREAT [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>]]...);
索引可以建立在该表的一列或多列上。
次序表示升序或者降序表示,升序:ASC,降序:DESC。缺省值:ASC
UNIQUE表示索引的每一个索引值只对应唯一的数据记录。
CLUSTER表示要建立的索引是聚簇索引。
注意:如果是含重复值的属性列不能建立UNIQUE索引,
聚簇索引,基表中的数据也需要按指定的聚簇属性的升序或降序存放。
ALTER语句
ALTER语句用于修改各表项的内容,其语句格式如下所示:
1 | ALTER TABLE <表名> |
-表名:要修改的基本表
-ADD子句:增加新列和新的完整性约束条件
-DROP子句:删除指定的完整性约束条件
-MODIFY子句:用于修改名列名和数据类型
-只能间接删除属性列
* 把表中要保留的列及其内容复制到一个新表中
* 删除原表
* 再将新表命名为原表名
-不能修改完整性约束
-不能为已有列增加完整性约束
举例:向Student表中增加“入学时间”列,其数据类型为日期型。
ALTER TABLE Student ADD StudentCome DATE
DROP语句
DROP语句用于删除表项,其语句格式如下所示:
DROP TABLE <表名>;
-系统从数据字典中删去1、该基本表的描述;2、该基本表上的所有索引的描述。
-系统从文件中删去表中数据
-表上的视图仍然保留,但无法引用
举例:删除Student表。DROP TABLE Student
数据库操作语句
查询语句
查询语句表达式如下所示:
1 | SELECT [ALL|DISTICT] |
-SELECT子句:指定要显示的属性列
-FROM子句:指定查询对象(基本表或视图)
-WHERE字句:指定查询条件
-GROUP BY字句: 对查询结果按指定列的值分组,该属性列值相等的元组为一个组。通常会在每组中作用集函数。
-HAVING短语:筛选出满足指定条件的组
-ORDER BY子句:对查询结果表按指定列序的升序排序或者降序排序
WHER子句
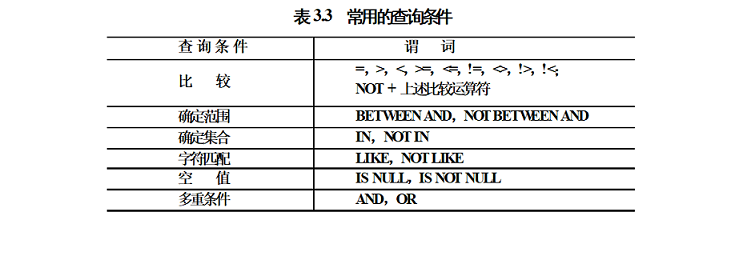
- 确认范围: BETWEEN…AND… / NOT BETWEEN…AND…比如
1 | SELECT Sname,Sdept,Sage |
确认集合:IN <值表> NOT IN <值表>。<值表>:用逗号分隔的一组取值。比如
1
2
3SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ( 'IS','MA','CS' );字符串匹配:使用谓词LIKE或NOT LIKE [NOT] LIKE ‘<匹配串>’[ESCAPE‘<换码字符>‘]比如
1
2
3
4
5
6
7
8
9
10
11
12SELECT *
FROM Student
WHERE Sno = '95001';
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname LIKE ‘刘%’;
SELECT Cno,Ccredit
FROM Course
WHERE Cname LIKE 'DB\_Design' ESCAPE '\'
使用换码字符将通配符转义为普通字符,ESCAPE换码字符涉及空值的查询:使用谓语 IS NULL 或 IS NOT NULL
5类主要集函数
- 计数
- COUNT([DISTINCT|ALL]*)
- COUNT([DISTINCT|ALL]<列名>)
- 计算总和
- SUM([DISTINCT|ALL]<列名>)
- 计算平均值
- AVG([DISTINCT|ALL]<列名>)
- 求最大值
- MAX([DISTINCT|ALL]<列名>)
- 求最小值
- MIN([DISTINCT|ALL]<列名>)
-DISTINCT短语:在计算中要取消指定列中的重复值
-ALL短语:不取消重复值
-ALL为缺省值
使用集函数
1 | 例: |
GROUP语句与HAVING语句
- 使用GROUP BY进行分组
- 分组方法:按指定的一列或多列值分组,值相等的为一组。
- 使用GROUP BY子句后,SELECT子句的列名列表中只能出现分组属性和集函数
- GROUP BY子句的作用对象是查询的中间结果表。
- 使用HAVING语句筛选最终结果
- 只有满足HAVING短语语句指定条件的组才输出。
- HAVING短语与WHERE子句的不同:作用对象不同。WHERE基于表,HAVING作用于组。
1 | 查询选修了3门以上课程的学生学号 |
单表查询
查询只涉及一个表,是一种最简单的查询操作。
如果需要显示所有的列,并且按照原表顺序,可用SELECT *子句
如果要消除重复的内容,可加DISTICT语句,比如SELECT DISTICT StudentNumber
连续查询
同时涉及多个表的查询称为连接查询。1
2
3
4
5
6SELECT Std.Sname, Std.Ssex, Sdept
FROM Std,StdC
WHERE Std.Sname = StdC.Sname /* 连接谓词 */
AND Std.Ssex = StdC.Ssex /* 连接谓词 */
AND StdC.Cno= ' 2 ‘ /* 其他限定条件 */
AND StdC.Grade>90; /* 其他限定条件 */
嵌套查询
概述:一个SELECT-FROM-WHERE语句称为一个查询块。将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询。1
2
3
4
5
6SELECT Sname 外层查询/父查询
FROM Student
WHERE Sno IN
(SELECT Sno 内层查询/子查询
FROM SC
WHERE Cno= ' 2 ');
数据更新语句
插入数据
插入单个元组
功能:将新元组插入指定表中。
语句格式:1
2
3INSERT
INTO <表名> [(<属性列1>[,<属性列2 >…)]
VALUES (<常量1> [,<常量2>]…)
- INTO子句
- 指定要插入数据的表名及属性列
- 属性列的顺序可与表定义中的顺序不一致
- 没有指定属性列:表示要插入的是一条完整的元组,且属性列属性与表定义中的顺序一致
- 指定部分属性列:插入的元组在其余属性列上取空值
- VALUES子句
- 提供的值必须与INTO子句匹配
插入子查询结果
功能:将子查询结果插入指定表中。
语句格式:1
2
3INSERT
INTO <表名> [(<属性列1> [,<属性列2>… )]
子查询:
- INFO子句与上相同。
- 子查询
- SELCET子句目标项必须与INFO子句匹配。
修改数据
功能: 修改指定表中满足WHERE子句条件的元组。
语句格式:1
2
3UPDATE <表名>
SET <列名>=<表达式>[,<列名>=<表达式>]…
[WHERE <条件>];
- SET子句
- 指定要修改的方式。
- WHERE子句
- 指定要修改的元组,缺省表示要修改所有的元组。
示例:1
2
3
4
5
6UPDATE SC
SET Grade=0
WHERE 'CS'=
(SELETE Sdept
FROM Student
WHERE Student.Sno = SC.Sno);
- 指定要修改的元组,缺省表示要修改所有的元组。
删除数据
功能: 删除指定表中满足WHERE子句条件的元组。
语句格式:1
2
3DELETE
FROM <表名>
[WHERE <条件>];
视图
建立视图
在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。
我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,我们也可以提交数据,就像这些来自于某个单一的表。
注释:数据库的设计和结构不会受到视图中的函数、where 或 join 语句的影响。
语句格式:1
2
3
4CREATE VIEW <视图名>
[(<列名> [,<列名>]…)]
AS <子查询>
[WITH CHECK OPTION];
- 组成视图的属性列名或全部省略或全部指定。
- 省略视图的各个属性列名,则隐含该视图由子查询中SELECT子句目标列中的诸字段组成。
- 必须明确指定组成视图的所有列名的情形。
- 某个目标列不是单纯的属性名,而是集函数或列表达式
- 目标列为*
- 多表连接时选出了几个同名列作为视图的字段
- 需要在视图中为某个列启用新的更合适的名字
- 子查询
- 不含ORDER BY子句和DISTINCT短语的SELECT语句
- WITH CHECK OPTION
- 透过视图进行增删改操作时,不得破坏视图定义中的谓词条件(即子查询中的条件表达式)
JOIN语句
有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 join。
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。
在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
示例:1
2
3
4
5SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
INNER JOIN Orders
ON Persons.Id_P = Orders.Id_P
ORDER BY Persons.LastName
- INNER JOIN(内连接):在表中存在至少一个匹配时,INNER JOIN 关键字返回行。
- JOIN: 如果表中有至少一个匹配,则返回行。
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行。
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行。
- FULL JOIN: 只要其中一个表中存在匹配,就返回行。